viernes, 16 de mayo de 2025
¡Lanzamos nuestro canal de YouTube
🎉 ¡Lanzamos nuestro canal de YouTube! 🚀
Te damos la bienvenida a Java España, un espacio creado para hablar de programación, tecnología y desarrollo moderno en español. 🇪🇸💻
🎬 En nuestro primer video nos hacemos una gran pregunta:
¿Ha muerto la Programación Orientada a Objetos? 🤯
Exploramos por qué cada vez más lenguajes y herramientas modernas están dejando atrás la OOP para adoptar la composición, la programación funcional y otros paradigmas más declarativos.
👉 Si eres desarrollador, estás aprendiendo o simplemente te apasiona la evolución del software, este video es para ti.
📺 Mira el video completo aquí: [enlace al video]
🔔 ¡Suscríbete y sé parte de la comunidad Java España desde el inicio!
#JavaEspaña #Programación #DesarrolloSoftware #ProgramacionFuncional #OOP #TendenciasTech2025
https://youtu.be/P3Bh6k90014
viernes, 15 de mayo de 2020
5 métodos de crear un Singleton en Java
1. Inicialización forzada (eager)
public class EagerInitializedSingleton {
private static final EagerInitializedSingleton instance = new EagerInitializedSingleton();
//constructor privado para evitar el acceso directo
private EagerInitializedSingleton(){}
public static EagerInitializedSingleton getInstance(){
return instance;
}
}Mejor evitar este tipo porque:1) Este singleton viene instanciado cada vez que se lanza toda la aplicación
2) Si este singleton tiene acceso a muchos recursos - el tiempo de lanzar tu aplicación va ser muy largoUtiliza mejor el método "lazy"martes, 8 de octubre de 2019
Dropdown de los países (lista alfabética, metiendo algunos países por arriba)
Antes de ayer he tenido la necesidad de crear una lista de los paises para un drop down en nuestro sitio web.
- La lista se debe presentar en el orden alfabético
- La lista debe ser localizada - los nombres de los países se presentan en el idioma elegida por el usuario ("España" en español, pero "Espagne" en francés, etc)
- La lista debe siempre empezar por algunos países predifinidos (p.e. Suiza, Alemania, Austria) y que luego viene el resto:
- La lista se debe presentar en el orden alfabético
- La lista debe ser localizada - los nombres de los países se presentan en el idioma elegida por el usuario ("España" en español, pero "Espagne" en francés, etc)
- La lista debe siempre empezar por algunos países predifinidos (p.e. Suiza, Alemania, Austria) y que luego viene el resto:
viernes, 30 de agosto de 2019
Node.JS + ExpressJS para el frontend: viva la simplicidad!
Un buenísimo y simplecisimo articulo para empezar a codear con Node.js + ExpressJS.
https://freshman.tech/learn-node/
https://freshman.tech/learn-node/
jueves, 7 de septiembre de 2017
Tutorial: comunicación entre Java y una base de datos H2 (con ejemplos): Parte 3 - Hibernate con Anotaciones
Hibernate, a pesar de sus ventajas, era bastante aparatoso. Todos estos ficheros XML de mapping, los DAO, la realización de DAO...Se te quitan hasta las ganas de escribir código. En la última parte hemos creado un proyecto con Hibernate y hemos visto todo el jaleo q se lleva Hibernate.
Los creadores de Hibernate tb se han dado cuenta de lo aparatoso q era y han venido con una idea fantástica: para que crear los ficheros especiales de mapping elos DAO, donde "mapeamos" nuestra BD (y básicamente duplicamos la información sobre nuestra BD), si podemos simplemente escribir los nombres de las columnas encima los campos en los ficheros de entity:

La información que estaba en DAO y los ficheros Mapping viene metida cómodamente en los ficheros "entity" en forma de las anotaciones:
Los creadores de Hibernate tb se han dado cuenta de lo aparatoso q era y han venido con una idea fantástica: para que crear los ficheros especiales de mapping elos DAO, donde "mapeamos" nuestra BD (y básicamente duplicamos la información sobre nuestra BD), si podemos simplemente escribir los nombres de las columnas encima los campos en los ficheros de entity:

La información que estaba en DAO y los ficheros Mapping viene metida cómodamente en los ficheros "entity" en forma de las anotaciones:
viernes, 25 de agosto de 2017



martes, 22 de agosto de 2017
Tutorial: comunicación entre Java y una base de datos H2 (con ejemplos): Parte 2 - Hibernate con XML
El tiempo pasaba y JDBC, con lo simple que era, tenía sus desventajas:
- El cambio de la BD? De Oracle a SQL Server ?

Venga - a parar el servidor, recompilar todo el proyecto y reiniciar el servidor. A un banco de parar su servidor de la producción por, digamos, una media hora, puede ser un problema....
- Fiabilidad
Si haces un pequeño programa para tu universidad o una pequeña empresa - no lo vas a notar. Pero que pasa, si tu aplicacion Java va ser ejecutada por miles de usuarios cada segundo? Imagina que 2 usuarios quieren a la vez actualizar la misma línea de BD, quien gana?
Por este motivo varios chavales han empezado a crear unas herramientas que se llamaban ORM (Object-Relational Mapping), donde las tablas y las relaciones entre las tablas en la BD están "mapeadas" en el código Java a traverso de los ficheros mapping XML (y mas tarde con el código Java usando las anotaciones). Al mismo tiempo la manera, en que una aplicación Java guarda los datos en una BD ha tambien evolucionado y así apareció la capa de Persistance, donde los datos primero estaban guardados en los objetos simples de Java (POJO) que tenían los setters y getters y luego una sesión les guardaba en la base de datos a traverso de una transacción.
Los primeros eran los de JBoss que han creado Hibernate en 2001. En verdad hay un montón de frameworks ORM - IBATIS, EclipseLink y no solo en Java, pero tb en C#, PHP, etc. Pero Hibernate sigue siendo una de mas simples y mas populares.
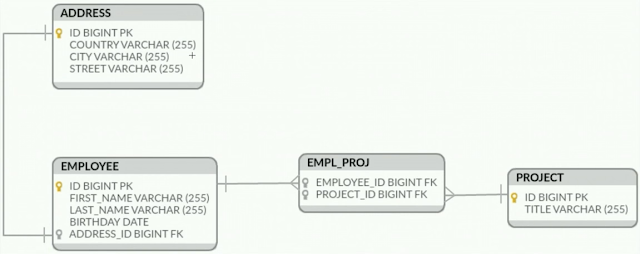
Hoy vamos modificar nuestro proyecto que hemos creado un la parte 1 y en vez de utilizar la conexión a traverso de un driver JDBC, utilizamos Hibernate. Voy pegar otra vez la esquema de la BD:
Aquí en vez de abrir y cerrar la conexión manualmente, utilizamos una sesión Hibernate que actualiza las tablas a traverso de un mapping XML. El mapping XML refleja le estructura de una tabla SQL en un file XML.

- El cambio de la BD? De Oracle a SQL Server ?

Venga - a parar el servidor, recompilar todo el proyecto y reiniciar el servidor. A un banco de parar su servidor de la producción por, digamos, una media hora, puede ser un problema....
- Fiabilidad
Si haces un pequeño programa para tu universidad o una pequeña empresa - no lo vas a notar. Pero que pasa, si tu aplicacion Java va ser ejecutada por miles de usuarios cada segundo? Imagina que 2 usuarios quieren a la vez actualizar la misma línea de BD, quien gana?

Por este motivo varios chavales han empezado a crear unas herramientas que se llamaban ORM (Object-Relational Mapping), donde las tablas y las relaciones entre las tablas en la BD están "mapeadas" en el código Java a traverso de los ficheros mapping XML (y mas tarde con el código Java usando las anotaciones). Al mismo tiempo la manera, en que una aplicación Java guarda los datos en una BD ha tambien evolucionado y así apareció la capa de Persistance, donde los datos primero estaban guardados en los objetos simples de Java (POJO) que tenían los setters y getters y luego una sesión les guardaba en la base de datos a traverso de una transacción.
Los primeros eran los de JBoss que han creado Hibernate en 2001. En verdad hay un montón de frameworks ORM - IBATIS, EclipseLink y no solo en Java, pero tb en C#, PHP, etc. Pero Hibernate sigue siendo una de mas simples y mas populares.
Hoy vamos modificar nuestro proyecto que hemos creado un la parte 1 y en vez de utilizar la conexión a traverso de un driver JDBC, utilizamos Hibernate. Voy pegar otra vez la esquema de la BD:
Aquí en vez de abrir y cerrar la conexión manualmente, utilizamos una sesión Hibernate que actualiza las tablas a traverso de un mapping XML. El mapping XML refleja le estructura de una tabla SQL en un file XML.

Suscribirse a:
Entradas (Atom)